更新于:2023-11-22 23:30
一、参考资料
参考上篇文章《基于linux的通用格式转换》中提到的微软官方 OfficeVBA 接口文档,仔细看一下能得到很多信息。有 Document、Pane.Pages、HeadersFooters、Field、Shape、Table、InlineShape、OMath、Paragraph、Range、Word、Character 等。
仔细看完接口文档定义后,会觉得微软在文档方面造诣真的是业界第一,但微软接口定义但对象过于复杂,对于我们去学习并且自己定义一套简单但数据结构有一定难度。因此我们按照自己对文档对理解,获取一些核心对文档结构信息即可。用一套数据结构描述一篇文档,对于微软而言是无比巨细对描述出来,而对于我们只需要简单对简单描述即可(即满足业务需求并且后期能拓展即可)。
二、抽取文档基本结构信息
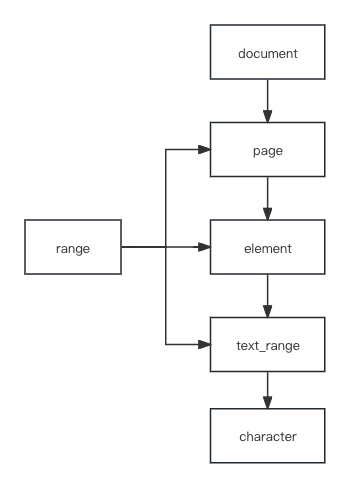
针对上面对描述,我们简单抽取出来一些概念,Document、Page、Element、Range、Character。分别表示文档、页、文档元素(文档结构)、文本区域、字符。
1、Document
Document 就是一个完整对文档对象,内置的属性都是用于描述一篇文档的信息。
2、Page
Page 表示文档中一页一页的对象,内置的属性都是用于描述特定页的信息。
3、Element
Element 是参考了微软定义的 HeadersFooters(页眉页脚)、Field(目录域)、Shape(绘图层对象)、Table(表格)、InlineShape(内嵌对象,待指图像)、OMath(公式)、Paragraph(段落) 等对象的统一定义。考虑到部分文档元素在文档中会存在跨展示页形式,可自行继承或衍生出跨页元素。
4、Range
Range 在微软 Office-VBA 接口文档中很抽象,它表示一个连续区域。也就是说它可以大到 Document,小到 Character。过于抽象的定位不太适合放在 Element 与 Character 之间,但是可以用它继承/衍生一个新的概念,文本区域(仅表达元素内的一段连续字符的范围),TextRange。
5、Character
Character 表示一个字符,内置的属性都是用于描述一个字符的信息。
三、结构图
四、代码展示
下面代码提供了一个很简洁的对象定义,参考微软接口文档,还需要借用指针把上层对象指向到底层对象,双向连接;还需要进行编写存储器,用于对象 Serialization/Deserialization 操作;最后针对 Element 的统称,需要细化一下成各种文档元素,类似微软官方定义的那种,毕竟每种元素的结构有一定差异。
class Range(object):
def __init__(self, x, y, width, height):
self.x = x
self.y = y
self.width = width
self.height = height
class Document(object):
def __init__(self, page_list):
self.page_list = page_list
class Page(Range):
def __init__(self, width, height, page_num, element_list):
Range.__init__(self, 0, 0, width, height)
self.page_num = page_num
self.element_list = element_list or []
class Element(Range):
def __init__(self, text_range_list, element_type):
x, y, width, height = self.get_element_region(text_range_list)
Range.__init__(self, x, y, width, height)
self.text_range_list = text_range_list or []
self.element_type = element_type
@staticmethod
def get_element_region(text_range_list):
x, y, width, height = 0, 0, 0, 0
if text_range_list:
start_char = text_range_list[0].character_list[0]
x1, y1 = start_char.x, start_char.y
x2, y2 = start_char.x + start_char.width, start_char.y
for text_range in text_range_list:
for character in text_range.character_list:
x1 = min(character.x, x1)
y1 = min(start_char.y - character.height, y1)
x2 = max(character.x + character.width, x2)
y2 = max(start_char.y, y2)
x, y, width, height = x1, y1, x2 - x1, y2 - y1
return x, y, width, height
class TextRange(Range):
def __init__(self, character_list):
if character_list:
start_char, end_char = character_list[0], character_list[-1]
x = start_char.x
y = start_char.y
width = end_char.x + end_char.width - x
height = max([char.height for char in character_list])
else:
x, y, width, height = 0, 0, 0, 0
Range.__init__(self, x, y, width, height)
self.character_list = character_list
class Character(Range):
def __init__(self, x, y, width, height, page_num, char, font_name=''):
Range.__init__(self, x, y, width, height)
self.page_num = page_num
self.char = char
self.font_name = font_name
if __name__ == '__main__':
page_list = []
for page_num in range(1, 3):
character_list = []
for index in range(1, 11):
character_list.append(Character(index, index, 1, 1, page_num, str(index)))
text_range = TextRange(character_list)
paragraph = Element([text_range], element_type='paragraph')
page_list.append(Page(1123, 794, page_num, [paragraph]))
document = Document(page_list)
后续会新增代码仓,并完善数据结构的定义,Github 地址 。
五、小结
通过上面讲解,我们定义一个简单的文档结构化所需的数据结构(待完善),后面文章我们将通过一些开源工具进行解析文件,并且将其构建成上面定义的对象。