更新于:2023-11-28 21:35
一、前提介绍
在实现解析之前,我们需要保证的是前两篇文章已经熟悉并且相关服务已经实现。因为我们针对 word/excel/ppt/pdf 等不同格式等文件解析,都是需要统一转换成 PDF 格式进行解析。在《文档结构化解析》 文章中提供的四种方案也都是基于 PDF 处理的,本篇文章按照第三种方案进行实现。
二、服务流程图
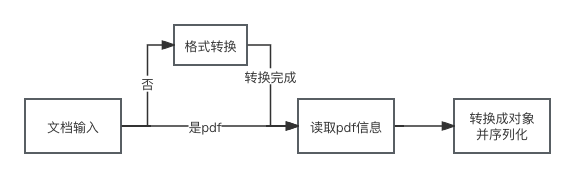
三、开源的PDF解析工具介绍
1、pdfminer
pdfminer 分支版本有很多,当前介绍一个会在维护对分支版本 pdfminer.six ,GitHub 仓库。
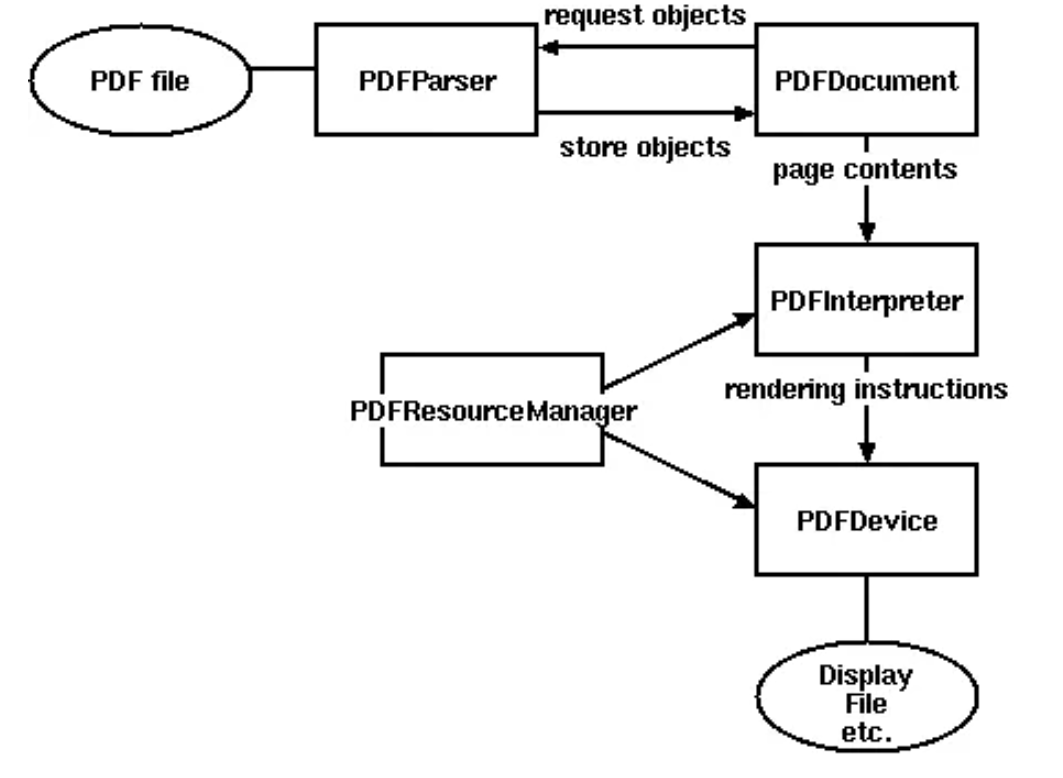
PDFMiner 有两个核心类,PDFParser 和 PDFDocument,除了这两个模块还有以下几个模块来配合使用,下图也表示了 PDFMiner 各模块之间的关系。
| 模块名 | 说明 |
|---|---|
| PDFParser | 从文件中获取数据 |
| PDFDocument | 存储文档数据结构到内存中 |
| PDFPageInterpreter | 解析page内容 |
| PDFDevice | 把解析到的内容转化为你需要的东西 |
| PDFResourceManager | 存储共享资源,例如字体或图片等 |
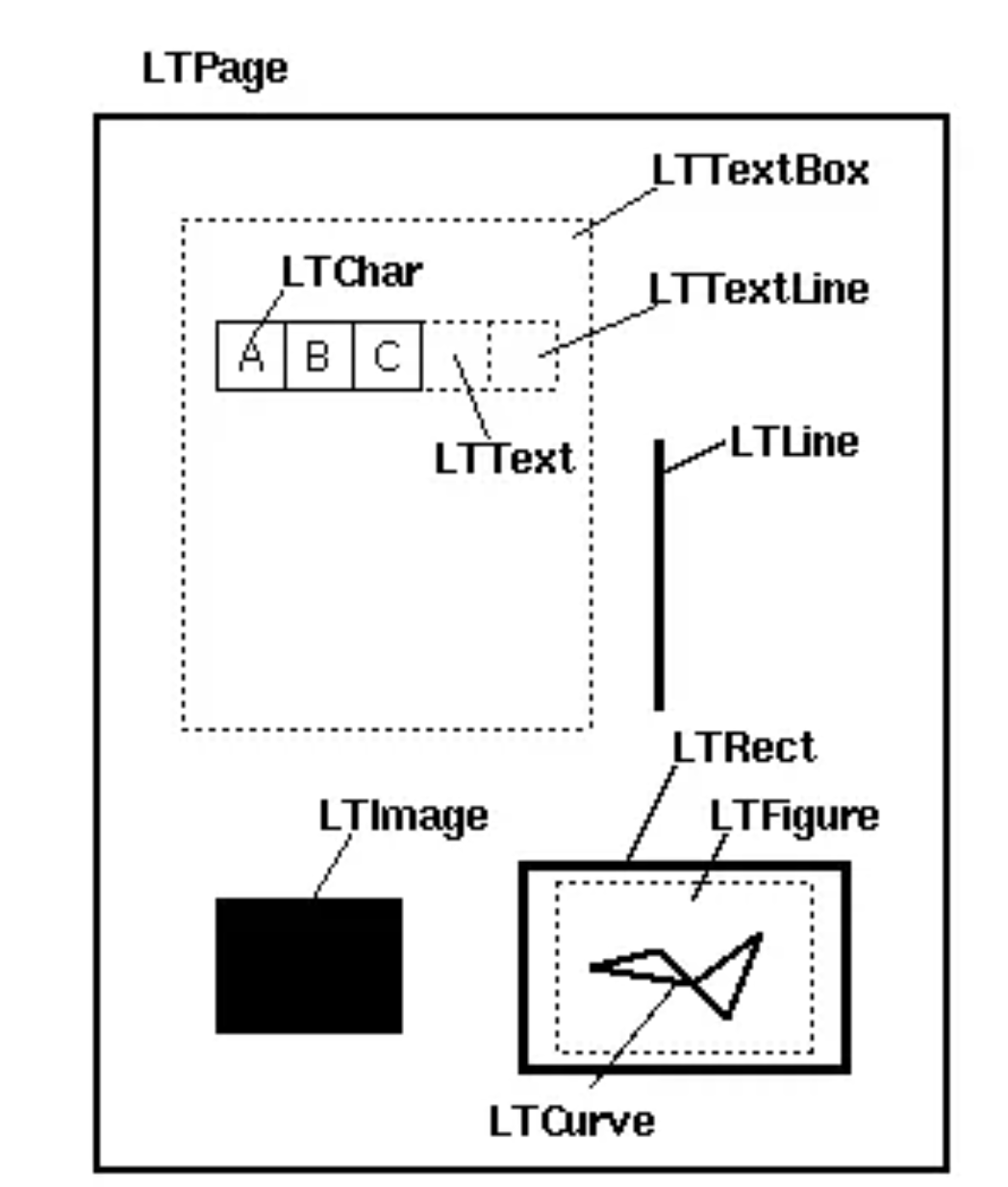
在解析过程中,有一些对象需要提前了解一下。
| 对象名 | 对象说明 | 备注 |
|---|---|---|
| LTPage | 代表一个完整的页面,可以包含子对象 | 例如:LTTextBox, LTFigure, LTImage, LTRect, LTCurve 和 LTLine |
| LTTextBox | 它包含 LTTextLine 对象的列表,代表一组被包含在矩形区域中的文本 | 注意:该box是根据几何学分析得到的,并不一定准确地表现为该文本的逻辑范围,get_text()方法可以返回文本内容 |
| LTTextLine | 包含一个LTChar对象的列表,表现为单行文本 | 字符表现为一行或一列,取决于文本书写方式,get_text()方法返回文本内容 |
| LTChar | 表示一个在文本中的真实的字母,作为一个unicode字符串 | LTChar 对象有真实的分隔符 |
| LTAnno | 表示一个在文本中的真实的字母,作为一个unicode字符串 | LTAnno 对象没有,是虚拟分隔符,按照两个字符之间的关系,布局分析器插入虚拟分隔符 |
| LTFigure | 表示一个被 PDF Form 对象使用的区域 | pdf form适用于目前的图表(present figures)或者页面中植入的另一个pdf文档图片,LTFigure对象可以递归 |
| LTImage | 表示一个图形对象,可以是JPEG或者其他格式 | 但 PDFMiner 目前没有花太多精力在图形对象上 |
| LTLine | 表示一根直线 | 用来分割文本或图表(figures) |
| LTRect | 表示一个矩形 | 用来框住别的图片或者图表 |
| LTCurve | 代表一个贝塞尔曲线 |
2、pymupdf
PyMuPdf 工具库在 1.20.X 版本进行了接口名称变更的差异,可以的话建议大家使用最新版本。官方文档 ,GitHub 仓库,pymupdf 可以理解成是 mupdf 的 python 版本工具库。在国内做文档解析需求的几家公司,该工具基本都用过,国内 CSDN 上的资料关于 python 处理 pdf 貌似 pymupdf 文档的写作时间是比较新的,由于官方的更新速度快,国内网站的资料比较全比较多。
3、borb
borb ,做为一款新的国外开源组件,虽然也支持中文,但是测下来速度较慢,特别是在处理带有中文的 PDF 文件时需要加载字体,使用起来不是很便捷。下面提供官方的一段代码展示,可以自行通过pip3 install borb==2.1.3安装体验。
from decimal import Decimal
from pathlib import Path
from borb.pdf import Document
from borb.pdf import PDF
from borb.pdf import Page
from borb.pdf import Paragraph
from borb.pdf import SingleColumnLayout
from borb.pdf.canvas.font.font import Font
from borb.pdf.canvas.font.simple_font.true_type_font import TrueTypeFont
pdf = Document()
print("add an empty Page")
page = Page()
pdf.add_page(page)
print("use a PageLayout (SingleColumnLayout in this case)")
layout = SingleColumnLayout(page)
font_path: Path = Path('Chinese_font.ttf')
font: Font = TrueTypeFont.true_type_font_from_file(font_path)
print("add a Paragraph object")
layout.add(Paragraph("他们所", font_size=Decimal(20), font=font))
print("store the PDF")
with open(Path("output.pdf"), "wb") as pdf_file_handle:
PDF.dumps(pdf_file_handle, pdf)
print("load the PDF")
with open(Path("output.pdf"), "rb") as pdf_file_handle:
doc = PDF.loads(pdf_file_handle)
4、其他
pikepdf 、pdfrw 、PyPDF4 ,由于对应的社区更新慢甚至有的仓库不再维护,在此就不具体描述了。
四、代码实现
下面提供一段代码,数据结构基于上一篇文章中定义的简单结构。
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTChar, LTTextBoxHorizontal
from document_structure import Page, Character, TextRange, Element, Document
class PdfParse:
def __init__(self, parse_pdf_path):
self.parse_pdf_path = parse_pdf_path
def gen_document_by_pdfminer(self):
page_list = []
for page_idx, lt_page in enumerate(extract_pages(self.parse_pdf_path)):
element_list = []
for lt_text_box in lt_page._objs:
if not isinstance(lt_text_box, LTTextBoxHorizontal):
continue
for lt_text_line in lt_text_box._objs:
text_range_chars = []
for lt_char in lt_text_line._objs:
if not isinstance(lt_char, LTChar):
continue
if lt_char.x0 >= 0 and lt_char.y0 >= 0 and lt_char.width > 0 and lt_char.height > 0:
x, y = lt_char.x0, lt_page.height - lt_char.y0 - lt_char.height
width, height = lt_char.width, lt_char.height
char, font_name = lt_char._text, lt_char.fontname
text_range_chars.append(Character(x, y, width, height, page_idx + 1, char, font_name))
if text_range_chars:
text_range = TextRange(text_range_chars)
element_list.append(Element([text_range], element_type='paragraph'))
page_list.append(Page(lt_page.width, lt_page.height, page_idx + 1, element_list))
return Document(page_list)
def gen_document_by_mupdf(self):
...
if __name__ == '__main__':
pdf_parse: PdfParse = PdfParse('test.pdf')
document_1 = pdf_parse.gen_document_by_pdfminer()
后续会新增代码仓,并完善解析流程,Github 地址 。
五、小结
本篇文章首先介绍了简单的解析流程,之后介绍了开源的相关组件去读取pdf文件信息,然后构建成我们自定义的数据结构。通过上面以及本篇文章介绍,大家应该对文档结构化有了一定的了解以及可以实践的操作。后续文章会详细介绍相关的原理,代码仓也会慢慢的完善。