更新于:2023-12-08 16:30
一、高并发的重要性
在 Python 编程开发时,经常会遇到一些需要并发处理的任务。而高并发任务处理在现代编程中非常重要,特别是在处理大量数据或高性能计算时。Python 通过提供不同类型的执行器来应对不同种类的任务,主要分为I/O密集型和CPU密集型任务。了解这两种任务的处理方式对于编写高效的 Python 程序至关重要。
二、高并发任务分类
1、I/O 密集型任务
I/O密集型任务通常涉及到等待外部操作的完成,如文件读写、网络请求等。这种类型的任务不会占用太多 CPU 资源,因此多线程是处理这类任务的理想选择。推荐使用ThreadPoolExecutor,该工具是 Python 的concurrent.futures模块提供的一个线程池执行器,非常适合用于执行I/O密集型任务。
下面提供一段示例代码:
import concurrent.futures
import urllib.request
def load_url(url):
with urllib.request.urlopen(url) as conn:
return conn.read()
result_list = []
task_list = ["http://www.baidu.com", "http://www.google.com"]
concurrency = min(len(task_list), 5)
with concurrent.futures.ThreadPoolExecutor(max_workers=concurrency) as executor:
future_to_url = {executor.submit(load_url, url): url for url in task_list}
for future in concurrent.futures.as_completed(future_to_url, timeout=len(task_list) * 10):
result_list.append(future.result())
2、CPU 密集型任务
CPU密集型任务主要涉及到密集的计算操作,如数学运算或数据处理,这类任务应该使用进程池来实现并行计算。推荐使用ProcessPoolExecutor,该工具同样是 Python 的 concurrent.futures 模块中的一个执行器,用于分配CPU密集型任务到多个进程中。
下面提供一段示例代码:
import math
from concurrent.futures import ProcessPoolExecutor
def compute_factorial(number):
return math.factorial(number)
task_list = [1297337, 1116281, 104395303]
concurrency = min(len(task_list), 5)
with ProcessPoolExecutor(max_workers=concurrency) as executor:
result_iterator = executor.map(compute_factorial, task_list, timeout=len(task_list) * 1)
result_list = list(result_iterator)
3、混合型任务
混合型任务是指处理的任务既包含了 I/O 操作,也包含了 CPU 操作。但是考虑到性能方面还是建议大家使用进程池操作,但是你设置多少进程池的并发容量,实际用到机器 CPU 资源是达不到那个并发容量的。具体可以在实际场景使用时自己记录一下这个信息来计算任务所需 CPU 资源。
三、线程池/进程池的底层原理
在 Python 3.8 左右的版本中,concurrent.futures模块的线程池和进程池都采用了类似的设计原则。
1、Future
在很多编程语言中,多线程都会有一个 future 对象的概念,当前对象为空但未来值会填充。一般是子线程完成任务之后会把结果写到这个对象中,感兴趣的可以看一下官方源码from concurrent.futures import Future。
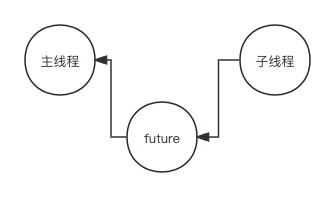
大概逻辑是主线程将任务放到线程池后得到了这个 future 对象,但对象但 result 此时为空,如果主线程调用 result() 方法获取结果,就会阻塞在条件变量上。此时子线程计算任务完成了就会立即调用 set_result() 方法将结果填充进 future 对象并唤醒阻塞在条件变量上的线程,也就是主线程,这时主线程立即醒过来并正常返回结果。
2、ThreadPoolExecutor
线程池内部维护了一个线程列表和一个工作队列。当提交一个任务时,它被放入队列中,池中的空闲线程会从队列中取出任务并执行,这个过程是自动管理的,开发者无需关心线程的生命周期。
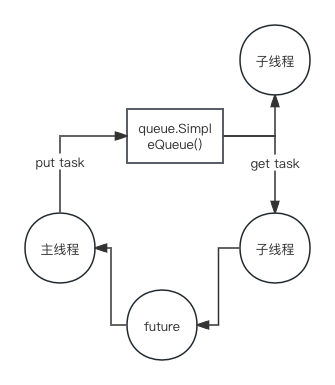
主线程和子线程交互有两个部分:
第一部分是主线程将任务传递给子线程,这里是通过 python 的内置的队列进行实现(线程安全的);当主线程将任务塞进任务队列后,由子线程们开始进行资源争夺,最终由一个线程抢到这个任务并处理任务;
第二部分是子线程将结果传递给主线程,执行完后将结果放进 future 对象就完成了这个任务的完整执行流程。
最后,我们在使用线程池时需要注意内存情况。由于所有线程共享同一内存空间,大量线程或大型任务可能会导致内存溢出等问题,因此在使用时一定要注意并发量的控制。
3、multiprocessing.Queue
该队列是专为跨进程通信设计的队列,它是 multiprocessing 模块的一部分,用于在不同的进程之间安全地传递消息或数据。我们通过from multiprocessing import Queue查看源码,在初始化时有这么一行代码self._reader, self._writer = connection.Pipe(duplex=False),通过构建一个单向的管道来实现的(管道是一种操作系统级别的 IPC 机制,允许一个进程写入数据,另一个进程读取数据)。当跨进程通信时,父进程通过 pickle 包将任务对象(对象很复杂易出现 pickle 报错)进行序列化并且写入管道,子进程得到数据后反序列化成对象执行任务。当子进程执行完之后将结果传递给父进程,是一样的流程(管道不一样)。
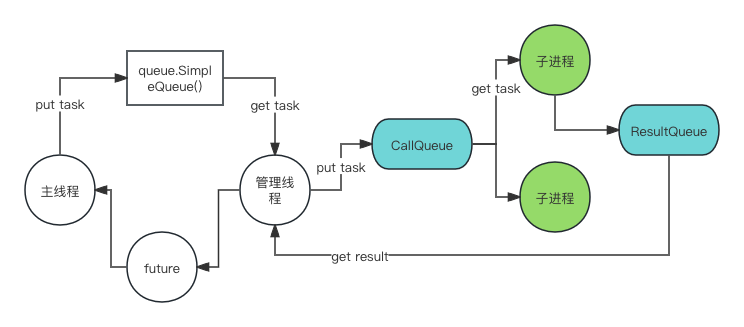
4、ProcessPoolExecutor
进程池的工作方式类似于线程池,但它创建的是进程而不是线程。Python 使用 multiprocessing 模块来创建和管理进程。由于进程间的隔离不共享内存空间,因此需要跨进程队列进行交互处理。
|======================= In-process =====================|== Out-of-process ==|
+----------+ +----------+ +--------+ +-----------+ +---------+
| | => | Work Ids | | | | Call Q | | Process |
| | +----------+ | | +-----------+ | Pool |
| | | ... | | | | ... | +---------+
| | | 6 | => | | => | 5, call() | => | |
| | | 7 | | | | ... | | |
| Process | | ... | | Local | +-----------+ | Process |
| Pool | +----------+ | Worker | | #1..n |
| Executor | | Thread | | |
| | +----------- + | | +-----------+ | |
| | <=> | Work Items | <=> | | <= | Result Q | <= | |
| | +------------+ | | +-----------+ | |
| | | 6: call() | | | | ... | | |
| | | future | | | | 4, result | | |
| | | ... | | | | 3, except | | |
+----------+ +------------+ +--------+ +-----------+ +---------+
上面是官方在代码包中敲写的时序图,并提供了英文描述整个流程。前面流程和线程池差不多,并且增加管理线程的概念。管理线程对应的进程(父进程)把上面主线程发下来的任务塞到 CallQueue 的跨进程队列时,子进程开始抢夺任务并且执行,执行完后由子进程把结果通过 ResultQueue 的跨进程队列返回给父进程,再由父进程的管理线程写入 future 对象。
四、总结
在处理高并发任务时,了解任务的类型是关键。对于I/O密集型任务,使用线程池 (ThreadPoolExecutor) 可以提高程序的响应速度和效率;而对于CPU密集型任务,使用进程池 (ProcessPoolExecutor) 可以充分利用多核 CPU 的计算能力。合理地使用这些工具和技术,可以显著提高 Python 程序的性能和效率。通过这篇教程,您应该能够更好地理解 Python 中的并发编程概念,并能够根据任务类型选择合适的并发处理方法。记住,正确地使用并发和并行编程技术,可以帮助您构建更快、更高效的应用程序。