更新于:2024-05-18 15:00
一、引言

上图所示,本篇文章主要对第三个处理单元的版面分析进行介绍,在 文档结构化解析 文章中就提到了多种方案,今天主要对《基于算法的通用文档解析实现》进行讨论。
这里所指的算法是深度学习的算法(CV方向),依靠深度学习的训练的模型在”通用”场景下能得到较满意的效果。而通过深度学习训练的模型进行文档版面识别的方法,已经成为当下版面解析的主流的方向。随着预训练模型的流行,深度神经网络的效果也逐渐提升。
主流的深度学习算法主要是目标检测算法、图像分割算法,通过将文档版面中对区域分类后再进行后续步骤处理。目标检测算法,主要是指从图像中识别出所需结果区域的过程,在对文档进行版面分析的需求中还是比较适用的。图像分割算法,是对输入图像中的像素区域打上类别标签的过程,因为是对像素进行区域分割识别,不会出现目标检测算法对识别结果出现区域重叠现象。下面我们会对这几种算法模型进行详细的介绍。
二、算法介绍
1、Faster R-CNN
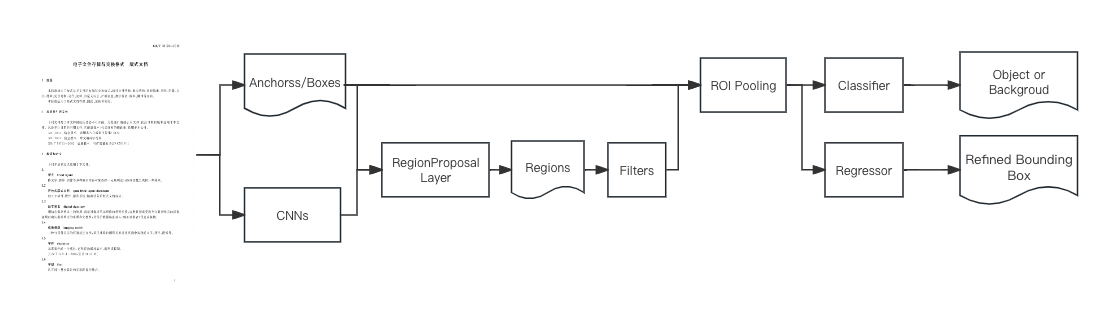
Faster R-CNN由Ross B.Girshick于 2016 年提出,是一种基于深度学习的目标检测算法模型。它通过引入区域提议网络(Region Proposal Network,RPN)和区域分类网络(Region Classification Network)的结构,实现了端到端的目标检测任务。Faster R-CNN通过首先生成候选区域,然后对这些候选区域进行分类和定位,从而实现高效而准确的目标检测。在结构上它能将目标检测任务需要的特征抽取、边框回归、分类等各个步骤都聚合在一个网络结构中,还创造性地使用RPN替代先前的区域搜索,模型识别速度不仅快,而且效果也好。
2、YOLO
YOLO(You Only Look Once)是一种流行的物体检测和图像分割模型,由华盛顿大学的Joseph Redmon和Ali Farhadi开发。YOLO于 2015 年推出,因其高速度和高精确度而迅速受到欢迎,下面是各版本简介。
2016年:发布的 YOLOv2 通过纳入批量归一化、锚框和维度集群改进了原始模型。
2018年:推出的 YOLOv3 使用更高效的骨干网络、多锚和空间金字塔池进一步增强了模型的性能。
YOLOv4 于 2020 年发布,引入了 Mosaic 数据增强、新的无锚检测头和新的损失函数等创新技术。
YOLOv5 进一步提高了模型的性能,并增加了超参数优化、集成实验跟踪和自动导出为常用导出格式等新功能。
YOLOv6 于 2022 年由美团开源,目前已用于该公司的许多自主配送机器人。
YOLOv7 增加了额外的任务,如 COCO 关键点数据集的姿势估计。
YOLOv8 是 YOLO 的最新版本,由 Ultralytics 提供。YOLOv8 支持全方位的视觉 AI 任务,包括检测、分割、姿态估计、跟踪和分类。
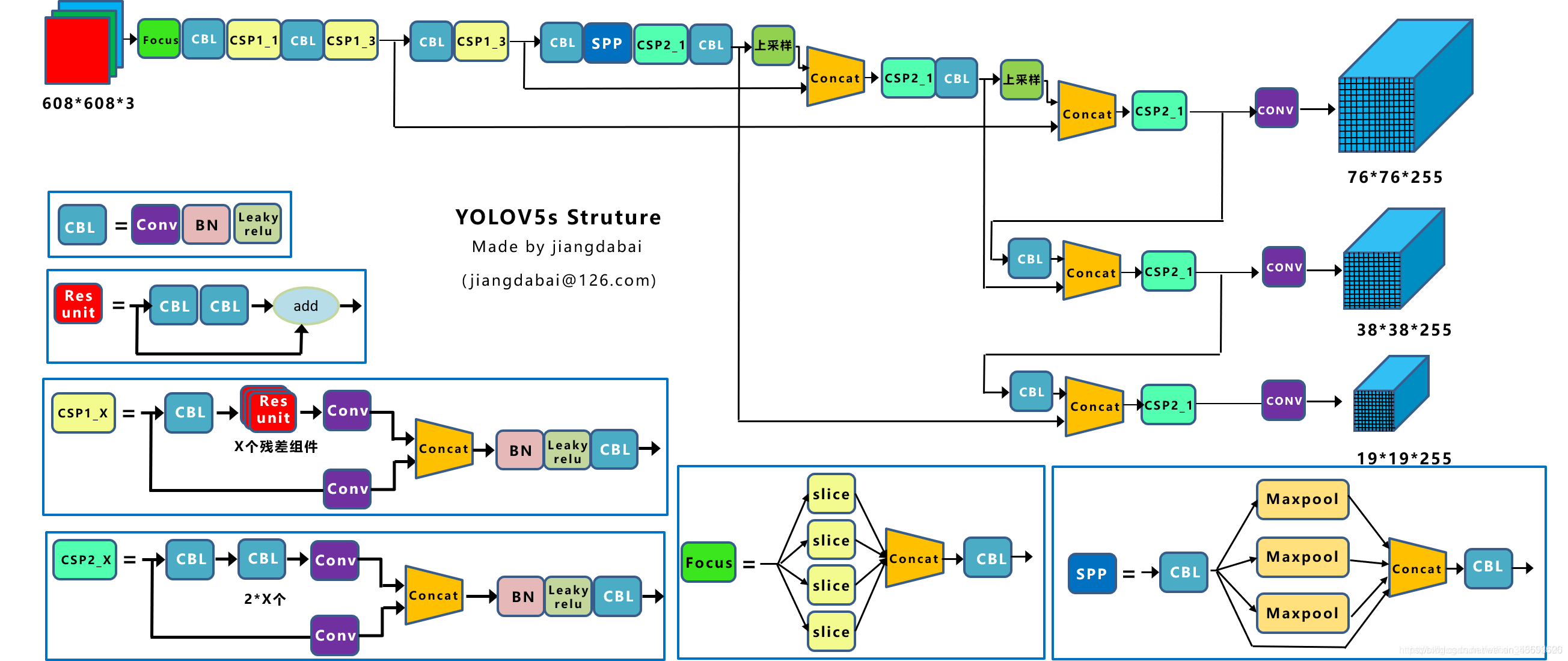
目前有不少公司在通过 YOLOv5 版本进行文档版面分析,它是一种单阶段目标检测算法。相较于传统的两阶段检测方法,YOLOv5具有更高的检测速度和更好的性能,而且模型可以做到数据增强、一致输入图像大小、最小化无消息黑框、类别平衡、模型压缩和加速等操作。
优点:
1、高速度:YOLOv5 采用单一的神经网络模型,可以实现快速的目标检测,适用于实时应用场景。
2、高性能:YOLOv5 在保持高速度的同时,具备良好的检测精度,可以实现准确的目标检测和实例分割。
3、简单易用:YOLOv5 提供了一系列预训练模型和训练代码,使用起来非常简单,适合快速搭建和部署。
缺点:
1、泛化能力有限:YOLOv5 在特定数据集上表现出色,但在一些特殊场景或复杂环境下,其泛化能力可能会受到影响。
2、需大量数据集:YOLOv5 的性能很大程度上依赖于训练数据的质量和数量,需要大量的标注数据进行训练,才能获得良好的检测效果。
3、针对小目标检测仍有挑战:与其他目标检测算法相比,YOLOv5 在小目标检测方面仍然存在一定挑战,特别是在高分辨率图像上的检测效果可能不如预期。
总结:YOLOv5 是一种快速、简单且性能良好的目标检测算法,模型也能很好的支持重叠目标的区域检查,适用于识别文档中的图像、水印、印章这类元素进行识别。
3、Detectron2
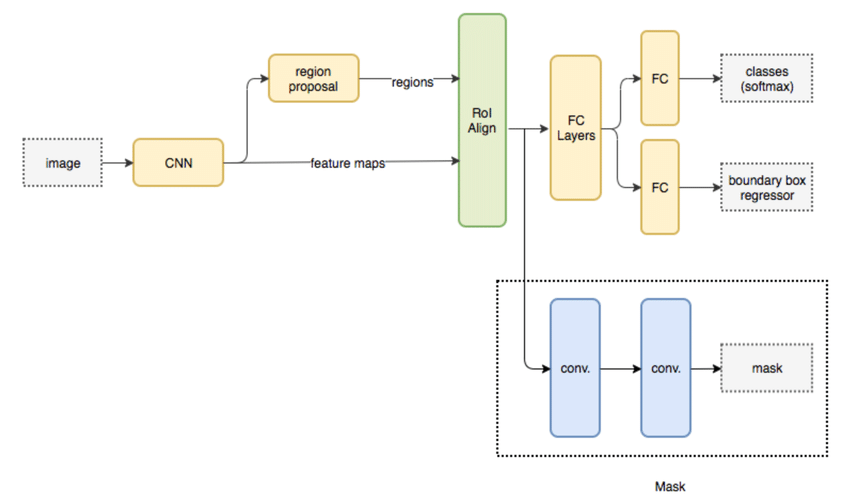
Detectron2 是Facebook AI Research团队开发的一款用于目标检测、实例分割和物体关键点检测的深度学习算法框架。它是Detectron框架的升级版本,基于 PyTorch 深度学习库,提供了一系列强大的模型和工具。其中对于Mask R-CNN模型在文档对版面识别效果上,还是比较亮眼的(获得2017年的 ICCV 的 best paper)。
Mask R-CNN 在Faster R-CNN的基础上增加了一个用于生成目标掩码的分支,从而实现了目标检测和实例分割的联合任务。通过在模型中引入额外的object mask输出,Mask R-CNN可以将目标检测任务转化为图像分割的输出,实现对目标的像素级别预测。同时Mask R-CNN中使用的ROIAlign模块取代了Faster R-CNN中的ROI Pooling,提高了像素级别预测的精度。ROIAlign操作能够更准确地对齐特征图中的区域,避免了信息的损失,有利于生成精确的目标掩码。在Mask R-CNN的架构中,目标检测和图像分割任务是并发进行的,这种设计使得模型能够同时实现目标检测和实例分割,提高了效率和准确性。
下面给出Mask R-CNN模型的优缺点:
优点:
1、精确的实例分割:能够生成目标的像素级别掩码,实现精确的实例分割。
2、多任务学习:同时处理目标检测和实例分割任务,提高了模型的效率和性能。
3、灵活性:可以适用于多种场景和数据集,具有较强的泛化能力。
4、广泛应用:在许多计算机视觉领域得到广泛应用,如物体识别、医学图像分析等。
缺点:
1、计算开销较大:由于需要同时进行目标检测和实例分割,模型的计算和存储开销较大。
2、模型复杂度高:模型结构相对复杂,需要大量的训练数据和计算资源进行训练和调优。
3、处理速度较慢:相比于单一任务的模型,处理速度较慢,不太适合实时应用场景。
总结:Mask R-CNN 模型在实例分割任务不仅能够生成精确的目标掩码,同时还能实现目标检测的功能。由于模型的复杂性和计算开销较大,需要在实际应用中权衡其性能和效率。在处理精细化的图像分割任务时具有优势,但处理速度方面有待提升。
4、GCN
GCN(Graph Convolutional Network)可以将文档表示为图结构,其中节点代表文档中的元素(如段落、标题、图像等),边表示元素之间的关系(如文本间的关联、图像与文本的关系等),然后利用 GCN 算法学习节点的特征表示,从而实现对文档的版面分析和解析。
通过GCN算法可以进行结构化信息提取(可以从文档的结构化信息中提取有用的特征,例如识别文本段落、标题、图像等元素,并分析它们之间的关系)、语义理解(通过学习节点之间的关联性,GCN 可以实现对文档的语义理解,例如识别文本段落的主题、图像的内容等)、版面分析(可以帮助理解文档的整体版面结构,包括页面布局、元素排列等,从而实现对文档版面的解析和分析)。
优点:
1、综合性:GCN 能够综合考虑文档中各个元素之间的关系,从而提高版面解析的准确性和鲁棒性。
2、适应性:GCN 算法灵活适用于不同类型的文档和版面结构,具有较好的泛化能力。
3、语义理解:通过学习节点之间的关联性,GCN 可以实现对文档的语义理解,提高了版面解析的效果。
缺点:
1、计算复杂度高:GCN 算法涉及图结构的建模和节点特征的学习,计算复杂度较高,需要消耗大量计算资源。
2、依赖数据质量:GCN 的性能很大程度上取决于输入数据的质量和标注,需要大量的标注数据进行训练和调优。
三、代码演示
下面通过一个开源库给大家演示一下,layout-parser ,它是一个基于Detectron2的开源模型,可以识别文档中的文本、标题、列表、表格和图像,并生成对应的布局信息。
import numpy as np
import cv2
import layoutparser as lp
image = cv2.imread('./paper-image.jpg')
image = image[..., ::-1]
config_path = 'lp://PubLayNet/tf_efficientdet_d0/config'
model = lp.Detectron2LayoutModel(
config_path='./config.yml',
model_path='./model_final.pth',
extra_config=["MODEL.ROI_HEADS.SCORE_THRESH_TEST", 0.8],
label_map={0: "Text", 1: "Title", 2: "List", 3: "Table", 4: "Figure"}
)
layout = model.detect(image)
drawn_image = lp.draw_box(image, layout, box_width=3)
drawn_image = cv2.cvtColor(np.array(drawn_image), cv2.COLOR_RGB2BGR)
cv2.imwrite('./paper-image-detected.jpg', drawn_image)
由于网络问题,现将相关配置文件和模型下载本地后再指定路径加载使用。安装教程请参考 官方文档 的说明。下图是在我机器上跑出的结果,和官方结果基本一致。

当获取到相关元素坐标区域后,针对不同元素区域再进行后续处理(表格解析、段落分析、图像解析等),最后生成完整的文档结构用于后续业务使用。
更新补充(2024-08-08),最近由上海人工智能实验室OpenDataLab团队在 github 上开源了的 PDF-Extract-Kit 中借助了 layoutlmv3 模型进行版面识别,抽取了其中版面识别的相关代码进行测试效果。
from modules.extract_pdf import load_pdf_fitz
from modules.layoutlmv3.model_init import Layoutlmv3_Predictor
img_list = load_pdf_fitz('/**/MinerU/demo/demo1.pdf', dpi=200)
layout_model = Layoutlmv3_Predictor('/**/PDF-Extract-Kit/models/Layout/model_final.pth')
layout_res = layout_model(img_list[0], ignore_catids=[])
模型下载请参考仓库的 README 即可,我按教程在 mac 机器的 cpu 环境跑了起来,跑了一张下面的效果图。由于模型是官方训练过的,测了一些研报效果也不错。对于版面类型不符合自己要求的,可以重新标注数据并调整标签信息再训练。

四、小结
上面我们介绍了CV方向算法的通用文档解析技术,通过分析文档的结构和内容,实现对文档的解析和理解,通过开源的layout-parser给大家介绍了算法使用场景。当落实到中文文档场景下,还需投入更多人力来(标注数据、训练模型)提升效果,达到企业级应用门槛。国产的百度模型 PaddleOCR ,我们也可以参考使用的。但文档结构化解析单纯从CV方向也不是可取的,还需要结合NLP方向的模型,比如BERT等,才能实现更全的文档解析。