更新于:2024-06-05 21:00
一、流程简介
首先将文档转换成图片,并且获取图片上公式的区域信息(OD 或者 版面识别的 layout 模型),将区域的像素信息放到公式识别模型中识别,模型输出latex的表达式,最后将 code 存储到结构化对象中。当前端需要展示可以把存储的latex-code再展示出来即可,MathJax则是js工具库中一个不错的选择方案,还有KaTeX等。
二、公式识别方案
1. 第三方应用
latexlive 应用网站,提供了识别图片公式的功能,一天有两次免费调用的机会,效果不错,接口调用有对应收费机制。
simpletex 应用网站,目前提供了免费的识别功能,识别效果也很不错,有免费和收费的接口调用。
tool.lu-latex 应用网站,网页端也提供了免费识别。
2. LaTeX-OCR
如果要解决收费问题,就需要寻找一些开源工具,LaTeX-OCR 是github上一款开源的CV模型,专门用于识别latex公式。官方提供了python-sdk以及镜像供我们使用。这里有个坑,按照官方教程提供的pip install "pix2tex[gui]"安装方式容易出现安装失败,gui 主要是提供一个可视化的软件界面(涉及qmake, pyqt6等)。实际我们只需要pip install pix2tex即可完成安装,然后调用代码使用。
from munch import Munch
from PIL import Image
from pix2tex.cli import LatexOCR
arguments = Munch({
'config': 'settings/config.yaml',
'checkpoint': 'checkpoints/weights.pth',
'no_cuda': True,
'no_resize': False,
})
img = Image.open('latex_demo.png')
model = LatexOCR(arguments=arguments)
latex_code = model(img)
print(latex_code)
上面代码是使用latex-ocr识别公式,需要注意的是首次运行时,LatexOCR 对象在初始化时会检查是否有模型文件并下载到安装包的位置,网络问题的可以提前下好,模型下载地址在download_checkpoints方法中,可在这里下载:weights.pth |
image_resizer.pth 。 |
如果觉得安装python-sdk的方式繁琐的话,可以用现成的docker镜像启动服务来体验,然后访问http://127.0.0.1:8501即可,相关命令如下。
docker run --rm -it -p 8501:8501 --entrypoint python lukasblecher/pix2tex:api pix2tex/api/run.py
version: '3.8'
services:
pix2tex-api:
image: lukasblecher/pix2tex:api
entrypoint: ["python", "pix2tex/api/run.py"]
ports:
- "8501:8501"
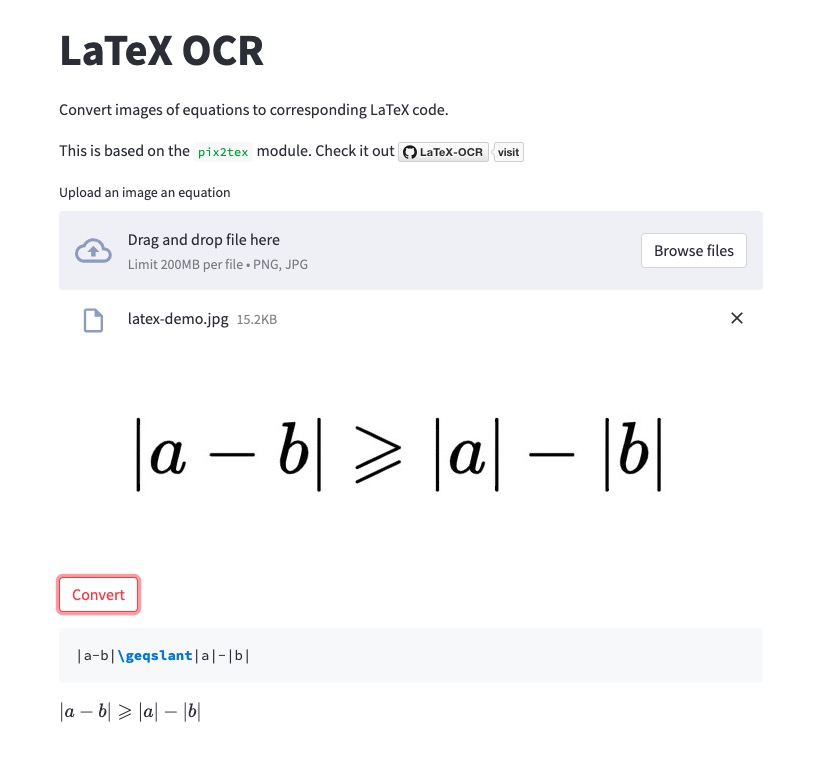
目前简单公式的识别准确率很高,稍微复杂些的公式就容易出现小字符识别错误现象,这类问题需要后续继续训练模型提高识别准确率,也有一些训练好的模型可以使用,RapidLatexOCR 和 Pix2Text 。
3. LLM
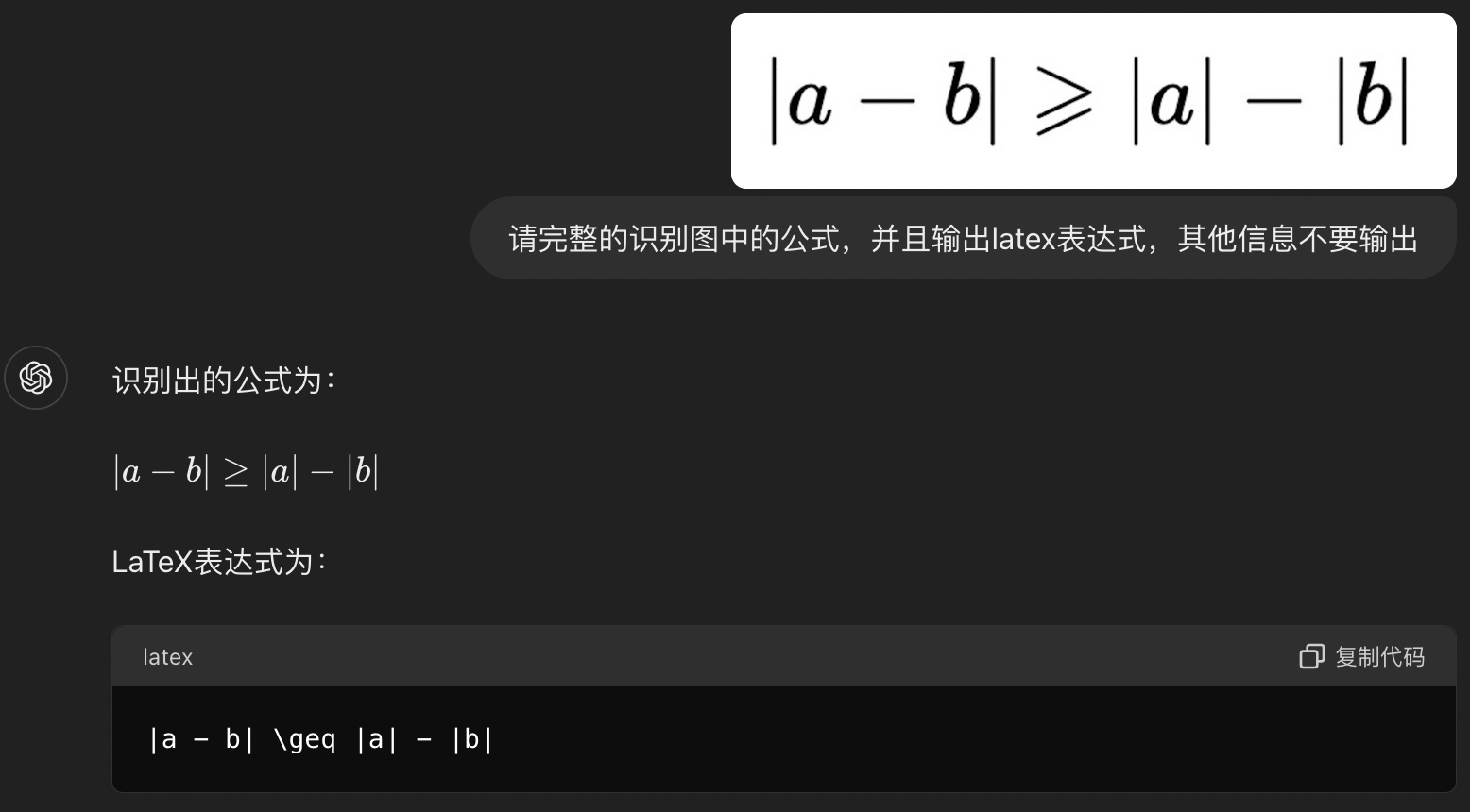
通过LLM模型(gpt-4o、gemini 等)识别图片中的公式,然后输出latex表达式。其中 gpt-4o 模型仅用简单的提示词,便能识别出很好的结果,实际使用当中调用相关模型的 api 接口即可。
4. 方案小结
方案一简单使用即可,识别量大时并不适应;方案二是目前常规且通用的,一般会选择这类方案;方案三的大模型接口调用也是不错的方案,简单上手,涉及 ToB 方向部署落地就不太行了(网络、数据安全等)。
三、LaTeX-OCR模型训练
当默认的模型不能满足业务场景识别时,就需要定制化专属的公式识别模型了。就需要收集一些数据、预处理数据集、训练模型。
公式数据集获取相对容易些,LaTeX-OCR 仓库也提供了 开源数据集 ,或者也可以自己随机生成一些latex-code,然后通过官方提供的工具(pix2tex.dataset.latex2png) 渲染成图片得到数据集,之后可尝试进行数据增强(旋转、缩放、加噪声、改亮度和对比度等)。有了图片和标签数据后,需要将其处理成 pickle 格式数据,要用到官方提供的(pix2tex.dataset.dataset)处理即可,最后修改 yaml 配置,开始在自己的机器上训练新的模型。
四、小结
本篇文章介绍了公式在文档结构化中的处理流程,并且提供了一些可选的公式识别方案,推荐了一个开源的LaTeX-OCR模型,并可以按官方教程训练自己的新模型。