更新于:2024-08-27 20:00
一、RAG简介
提到 RAG ,我们需要知道它是什么,做什么的,为什么需要它,以及什么时候用到它?针对这些问题,我们一点一点说明。
RAG是什么,做什么的?
RAG(Retrieval Augmented Generation)是一种结合了信息检索和自然语言生成两种方式的混合模型,通过检索外部知识库或数据源,并利用检索到的信息作为上下文,生成准确和有针对性的回答,从而提高自然语言处理任务的准确性和效果。
为什么需要RAG?
在gpt-3.5刚出现的时候,由于模型依赖于预训练阶段学习到的知识(训练的知识库内容是截止到 2019 年),因此在处理需要广泛知识的问题时可能会遇到困难。由于没有访问外部信息的途径,而且训练模型的成本过高,因此通过引入 RAG 模型的检索组件来解决信息滞后的问题,允许模型在生成回答之前访问相关的外部知识,并将其纳入生成过程,极大提高了模型的知识覆盖面和回答的准确性。
什么时候用到RAG?
1. 需要结合外部数据:企业等内部等有很多专属知识无法公开,需要借助 RAG 的检索和生成技术。
2. 需要生成准确回答:当前的 AIGC 技术存在幻觉,容易输出错误信息,当需要十分准确和有针对性的回答时(对话系统、智能客服等),RAG 可以利用检索到的信息作为上下文,生成合理且准确的回答。
3. 需要处理复杂和多样化的任务:当任务需要处理复杂和多样化的自然语言处理任务时(多轮对话、知识图谱问答等),RAG 可以提供强大的检索和生成能力,支持任务的完成。
二、RAG与文档结构化
看完上面介绍算是初步对 RAG 有一定的了解,之后就说明一下 RAG 和文档结构化有什么关联了。在读取外部数据源时,由于数据的种类多种多样,基本会包含文档类型的数据,从大量非结构化的文档中提取出信息,就需要用到文档结构化技术了。虽然文档结构化本质上是数据处理的任务步骤,但它是 RAG 最重要的前置工作之一。
为什么说文档结构化对 RAG 非常重要,不能直接用一些简单的工具库(类似langchain框架的文档加载器)去直接读取文档内容交给模型吗?确实可以这么做,但是非常不推荐。因为文档解析的不准确,会直接影响到后续的检索和生成阶段,导致整个 RAG 系统的性能下降。例如:文档分块会破坏原文的语义连贯性,影响信息的完整性;检索阶段会存在难以准确地找到与查询相关的文档部分,导致召回率不高;甚至可能会遇到内容错误识别或格式错误的问题,导致信息丢失或错误。
如果对于 RAG 整体架构不清晰的话,对于上面的描述可能会不太明白,下面章节我们来讲解一下 RAG 的工作流程。
三、RAG工作流程简介
下图内容大概分为两个步骤,左边是处理客户数据流程,右边是客户使用大模型查询问题的流程。
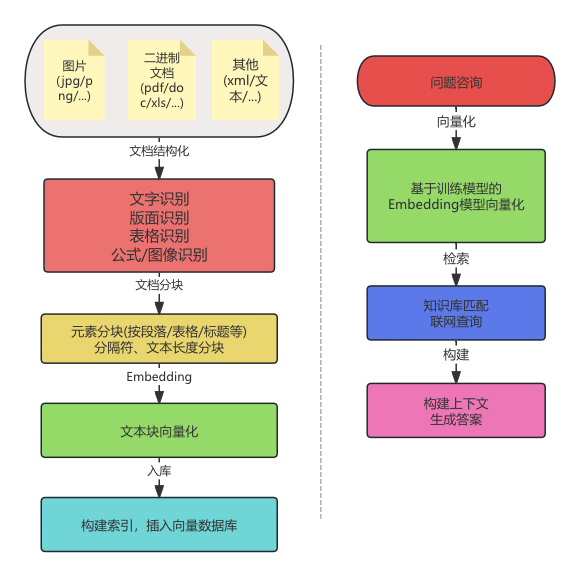
关于 RAG 工作流程,大致分为了文档结构化,文档内容分块、内容向量化、信息入库、用户检索、结果生成。文档结构化这个很早就有篇章介绍了,这里我们不再赘述,下面我们讲解一下后面的几个步骤。
1. 文档内容分块
分块过程是将一些大块文本拆分成许多较小的文本,使得文本数据更易于管理和处理。分块技术对于优化内容嵌入和提高检索效率至关重要,可以帮助我们显著提升从向量数据库中召回内容的相关性和准确性。
固定大小分块
简单直接的分块方法,设定每个块中的 token 量来分割文本,为保持语义上下文的连贯性,块之间会有一些重叠,下面通过langchain提供的工具来展示类似的效果。
from langchain_text_splitters.character import CharacterTextSplitter
text_splitter = CharacterTextSplitter(separator=",", chunk_size=15, chunk_overlap=3)
result = text_splitter.split_text("待分块的文本内容")
递归分块
递归分块:这种方法基于特定的分隔符(如句号、段落标记等)递归地分割文本,直到达到预设的块大小或满足其他停止条件。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(separators=["\n", " ", "。"], chunk_size=15, chunk_overlap=3)
result = text_splitter.split_text("待分块的文本内容")
基于文档结构的分块
该方法根据文档的逻辑结构(如段落、章节等)进行分块,以保持内容的组织性和连贯性,适用于具有明确结构化标记的文档,如 Markdown 或 HTML,因此很多文档结构化工具会将结果转换成这类格式。
from langchain.text_splitter import MarkdownTextSplitter
from langchain.text_splitter import HTMLHeaderTextSplitter
语义分块
语义分块考虑文本内容之间的语义关系,将文本划分为有意义的、语义完整的块。这种方法可以确保信息在检索过程中的完整性,从而获得更准确、更符合上下文的结果。
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = SemanticChunker(embeddings, chunk_size=1000, chunk_overlap=200)
documents = text_splitter.create_documents("待分块的文本内容")
其他分块
分块的逻辑有很多,除了langchain框架提供的一些方法,还有其他开源工具也可以使用。当然也可以自行定义一些的规则进行分块,例如根据句子长度、关键词出现位置等规则来划分文本块。
2.向量化
由于人类的文字是一种高级的信息表达方式,计算机无法直接理解它们。但通过将文本转换成数字,计算机就能更容易处理。Embedding 是一种将文本信息转换为数字的方法,这些数字可以构成一个数学向量。当我们计算不同向量之间的距离时,实际上就是在计算相对应文本之间的相似度。Embedding 的这种转换能够尽可能保留数据中的语义和特征关系。使用向量不仅提高了计算效率,还增强了模型对数据内在结构和关系的理解能力。
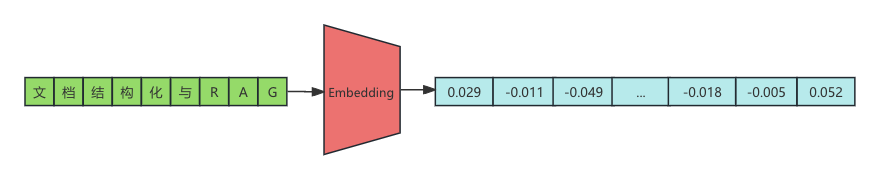
import os
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_google_genai import GoogleGenerativeAIEmbeddings
os.environ['GOOGLE_API_KEY'] = "gemini的api-key"
llm = ChatGoogleGenerativeAI(model="gemini-pro")
embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001")
embedded_query = embeddings.embed_query("文档结构化与RAG")
"""[0.02943110093474388, -0.011138400062918663, -0.04989973083138466, ..., -0.018653959035873413, -0.0056182267144322395, 0.05274665355682373]"""
Embedding 的模型选择有很多,这边提供几个 OpenAI Embedding ,Gemini Embedding ,BAAI Embedding ,JinaAI Embedding ,CohereAI Embeddings ,也可以参考 MTEB 排行榜 上的模型。
3.信息入库
经过分块和 Embedding 后得到文本块以及对应的向量值,把向量值存储在向量数据库中,也需要把文本块也存储起来。可以一起存在向量数据库,也可以分开存储(需要记录好两者之间的关联),以便在检索到相关向量后快速访问到原始内容。存储完信息之后,还需要给向量创建索引,提高检索相似向量时的速度。
这里我们通过 Chroma 数据库来举例,Embedding 模型不设置则是使用数据库默认提供的sentence-transformers/all-MiniLM-L6-v2模型(首次使用会自动下载模型)。首先使用pip install chromdb命令来安装依赖以及数据库,然后再启动数据库服务chroma run --path /data/chromadb_data --host 127.0.0.1 --port 10086。
import chromadb
chroma_client = chromadb.HttpClient(host='127.0.0.1', port=10086)
collection = chroma_client.get_or_create_collection(name='demo_1')
documents = ["小明喜欢烧烤和火锅", "小明的女朋友是小红", "小红喜欢吃东北菜", "小王的前朋友是小红"]
collection.add(documents=documents, ids=[f"id{i}" for i in range(len(documents))])
res = collection.query(query_texts=["小明女朋友"], n_results=1)
print(res['documents'])
实际业务场景中还有其他的向量数据库可以选择,例如FAISS、Pinecone、Weaviate等,这些数据库能够高效地管理和检索大规模的向量数据。
4. 用户检索
当用户提出查询问题时,直接将用户的内容转换为向量并进行检索可能得到的结果不佳(可以把上面章节代码多增加一些混淆语句测试)。可以在把查询语句转换成向量前进行一些预处理操作,以提高检索的准确性和生成的质量,下面我们简单介绍一些常见的处理操作。
意图识别:意图识别的目的是了解用户查询的目的或意图,从而帮助选择适当的检索策略或生成结果,下面通过 bart-large-mnli 来展示一下。
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli")
query = "请问Python中如何处理文件操作?"
candidate_labels = ["代码示例", "概念解释", "操作步骤", "问题解决"]
result = classifier(query, candidate_labels)
print(result['labels'])
"""操作步骤: 0.63,代码示例:0.188,问题解决:0.110,概念解释:0.090"""
关键词提取:从查询中提取出最关键的词语,去除不重要的信息,以集中在检索最相关的内容,下图通过TfidfVectorizer来展示一下。
from sklearn.feature_extraction.text import TfidfVectorizer
def extract_keywords(query):
vectorizer = TfidfVectorizer(stop_words='english')
X = vectorizer.fit_transform([query])
feature_names = vectorizer.get_feature_names_out()
tfidf_scores = X.toarray().flatten()
keywords = [feature_names[i] for i in tfidf_scores.argsort()[-3:][::-1]]
return keywords
query = "python 311 版本特性有哪些?"
print(f"提取的关键词: {extract_keywords(query)}")
同义词扩展:通过查询扩展技术将用户查询中的关键字替换或扩展为同义词,以提高查询覆盖范围,下图通过nltk来展示一下。
from nltk.corpus import wordnet
def expand_query(query):
synonyms = []
for word in query.split():
for syn in wordnet.synsets(word):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
expanded_query = " ".join(set(synonyms))
return expanded_query
query = "I like sandwiches"
expanded_query = expand_query(query)
print(f"扩展后的查询: {expanded_query}")
实体识别:实体识别技术用于识别查询中的关键实体(如人名、地名、组织名等),以便在知识库中更精确地找到相关内容,下面通过 bert-large-cased-finetuned-conll03-english 来展示一下。
from transformers import pipeline
nlp = pipeline("ner", model="dbmdz/bert-large-cased-finetuned-conll03-english")
query = "My name is mjtree and I live in Shanghai"
entities = nlp(query)
print(f"识别的实体: {entities}")
语义增强:通过上下文理解或语义分析,增强查询的语义表达,从而提高模型对查询的理解能力,下面通过 paraphrase-MiniLM-L6-v2 来展示一下。
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
query = "如何优化SQL查询性能?"
paraphrases = ["如何提高SQL查询速度?", "优化SQL语句的最佳方法", "如何加速数据库查询?"]
query_embedding = model.encode(query)
paraphrase_embeddings = model.encode(paraphrases)
scores = util.pytorch_cos_sim(query_embedding, paraphrase_embeddings)
print(f"相似度得分: {scores}")
对用户的检索语句做了相关处理后就将其转换成向量,然后去向量数据库中检索相似的向量并获取向量对应的原始内容信息。如果有联网查询功能,则可以把联网查询的信息先进行处理,再和向量库查询的信息一起整合起来交给下一步骤。
5.结果生成
1. 生成模型输入构建:将用户查询与整合的文本段落组合成一个上下文(llm_input = f"用户问题: {user_query}\n相关信息: {integrated_text}"),该上下文将作为生成模型的输入,以便生成模型可以基于这些相关内容生成准确的答案。
2. 生成式模型处理:将输入文本传递给大型预训练语言模型,生成最终的回答。
3.结果后处理:对生成的文本进行后处理(语法检查、敏感词过滤、去重、长度控制、格式优化等),以确保回答的质量和相关性。涉及多轮对话时,需考虑将前一轮的上下文信息纳入生成过程,以保持对话的连贯性。
四、常见RAG开源工具
- RAGFlow:这是一个基于深度文档理解的开源RAG引擎,它支持多种文档格式,如PDF、Word、PPT、Excel和TXT,并提供智能解析和文档处理的可视化。RAGFlow还提供了易于使用的API,可以轻松集成到企业系统中。项目地址:RAGFlow GitHub
- GraphRAG:由微软开源,GraphRAG是一种基于图的RAG方法,它可以对私有或以前未见过的数据集进行问答。它通过构建知识图谱和使用图机器学习技术来增强LLM在处理私有数据时的性能。项目地址:GraphRAG GitHub
- QAnything:这是一个支持任何格式文件或数据库的本地知识库问答系统,可以离线安装使用。它支持跨语种问答和粗排和精排的二阶段召回。项目地址:QAnything GitHub
- open-webui:这是一个自托管的WebUI,支持各种LLM运行程序,包括Ollama和OpenAI兼容的API。它支持安装和卸载模型、多模态模型、多用户管理等功能。项目地址:open-webui GitHub
- FastGPT:这是一个基于LLM的知识库问答系统,提供数据处理、模型调用等能力,并通过Flow可视化进行工作流编排。项目地址:FastGPT GitHub
- Langchain-Chatchat:这是一个基于ChatGLM等大语言模型与Langchain等应用框架实现的开源RAG项目,支持完全本地化推理,重点解决数据安全保护和私域化部署的企业痛点。项目地址:Langchain-Chatchat GitHub
- RAGxplorer:这是一个交互式的streamlit工具,用于支持构建基于RAG的应用程序,通过可视化文档块和嵌入空间中的查询来实现。项目地址:RAGxplorer GitHub
这些工具各有特点,可以根据你的具体需求选择合适的RAG工具来使用。