更新于:2024-04-04 14:30
一、简介
在前面的文章当中,介绍了一些深度学习算法的模型,通过模型对文档对进行版面元素识别分类。对于文档中的一些元素(页眉、页脚、标题、段落、图片、脚注等)只需要模型的区域即可,但是Table元素无法只能依靠一个区域就能解决的,我们需要获取表格中的线条信息来构建完整的表格结构。
二、表格类型介绍
表格的基本组成单位是单元格,表格的基本组成元素则是线条。线条的则是有线型、颜色、宽度、底纹等的相互组合形成线条,进而能构建成各式各样的表格样式给用户展示其信息。但这就会使得表格的线条信息不稳定,对于提取线条工作存在很大的阻碍。目前业内通过线条的样式将表格的线条侧重的分两类,分别是缺线表格、全线表格(满线表格)。
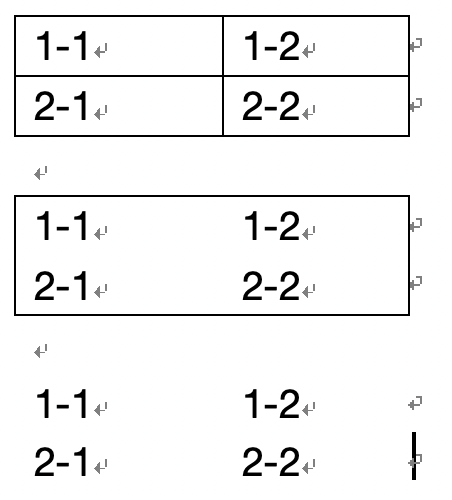
全线表格:常见的表格类型,线条结构完整;对于艺术、多线条的线型,只要线条不缺失都归纳到该类型。
缺线表格:不符合全线表格的表格则认为是缺线表格,其中无线表格是缺线表格的特殊样例。
虽然缺线表格甚至无线表格缺少线条信息,但是内部的单元格保持着一定间距信息,也是可以让模型能学习到的。
三、协议信息提取表格结构
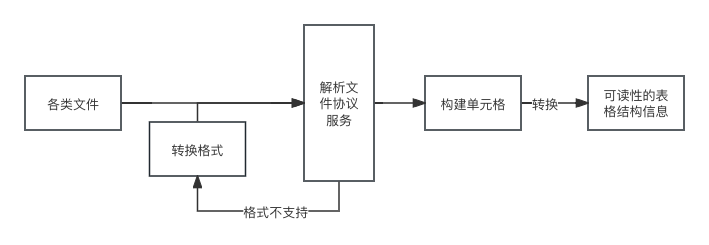
该方案就是针对不同文件格式,对其文件的的协议方法获取其线条信息,word 等文件可以使用ooxml协议,之间文章介绍过。pdf 可以借用mupdf等第三方工具获取线条信息,图片则是借用opencv对其二值化获取横竖线信息。
这些都是常见等文件格式的处理方案,对于其他不常见的格式,直接解析方便就可以直接处理,如果解析协议码成本大可以将其转换成上面的格式再处理,方案流程图如下。
四、算法模型提取表格结构
1、方案介绍
算法还是走的CV的方向,这个方案是比较常见。文件映射的图片信息放入模型中,识别得到表格区域以及线条信息,然后通过线条信息、字符距离、语义构建出单元格及合并单元格,流程可以参考下图。

2、线条识别方案
线条检测
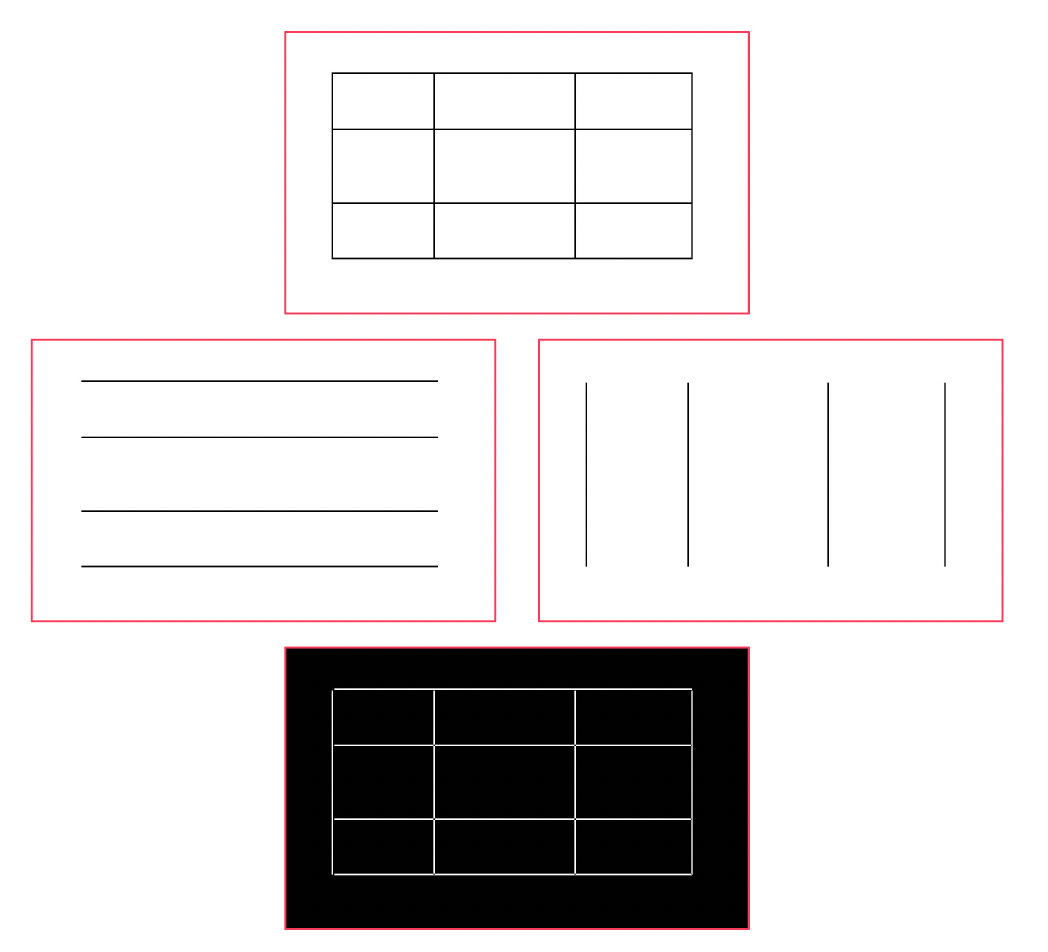
在全线表格场景中,通过opencv对文件页面映射出来的图片进行腐蚀膨胀(或者通过工具解析文件协议码中的线条信息),获取页面中的横线以及竖线信息,通过一些规则(横竖线是否闭环区域、区域大小等)判断得到相应的表格区域。此时表格中的单元格就是每个短的横竖线组成的小区域。当表格不是全线表格的时候,就需要图中短文本块之间的间距信息(甚至上下文信息)来确定单元格,而且还需要对构建好的单元格形状做判断,保证单元格不会出现⊥、∟这类非矩形形状,如果出现则需要补充线条来保证单元格的规范形状。
通过 opencv 识别图片中全线表格的线条信息,但是文档中除了表格的线条,还有很多噪声线条信息,需要合理的设置相应的参数来去除噪声信息,下面给出一段由 chatGPT 提供的简单代码查看效果。
import os
import cv2
import numpy as np
def save_lines_images(image_path):
print('读取图像')
image = cv2.imread(image_path)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
print('二值化处理')
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
print('检测横线')
horizontal_kernel = np.ones((1, 10), np.uint8)
horizontal_lines = cv2.erode(binary, horizontal_kernel, iterations=2)
horizontal_lines = cv2.dilate(horizontal_lines, horizontal_kernel, iterations=3)
print('检测竖线')
vertical_kernel = np.ones((10, 1), np.uint8)
vertical_lines = cv2.erode(binary, vertical_kernel, iterations=2)
vertical_lines = cv2.dilate(vertical_lines, vertical_kernel, iterations=3)
print('保存图片信息')
combined_lines = cv2.bitwise_xor(horizontal_lines, vertical_lines)
save_path = os.path.splitext(image_path)[0]
cv2.imwrite(save_path + '_horizontal_lines.jpg', horizontal_lines)
cv2.imwrite(save_path + '_vertical_lines.jpg', vertical_lines)
cv2.imwrite(save_path + '_combined_lines.jpg', combined_lines)
save_lines_images('demo.jpg')
目标检测+分割模型
上面讲述了一个基于线条的区域检测方案,也是个很简单的方案,在处理正式规范的电子文档时效果很好,但是在不少一部分场景下效果很差。例如客户随手拍一张照片(像素模糊、拍摄角度倾斜、电子设备摩尔纹等),又或者一个文件的复印机被多次复印成模糊不清文件等。因此需要不仅需要强大的OCR能力(给图片做前置处理,矫正、去水印摩尔纹印章、字符识别),还需要强大的ObjectDetection能力(检测表格区域),而ObjectDetection可以借用上一篇文章 基于算法的通用文档解析实现 中提到了YOLO模型来识别。当得到表格区域后,借用unet的像素分割模型得到图片中的横竖线信息,该方案有很高的鲁棒性和泛化性。
LGPMA
LGPMA 是一种表格识别的算法,是海康威视在 ICDAR2021 Table Recognition 赛道获得冠军的方案,目前已经在 github 上开源。该算法不同与上面的两种方案,它是通过识别单元格来推导整个表格,而不是通过表格区域和线条来推导单元格,是属于一种自底向上的方案。由于 ICDAR 比赛的数据是英文,中文场景效果差。这里推荐一个别人二开的仓库 LGPMA_Infer 可以自行再标注训练。
该方案能解决上面第二个方案解决不了一些场景(单元格存在背景色导致线条识别异常)。
UniTable
unitable ,一个迈向统一的表基础模型。官方介绍内容如下:
表格通过人类创建的隐含约定来传达事实和定量数据,这些约定通常对机器解析来说具有挑战性。之前关于表格识别(TR)的工作主要集中在可用输入和工具的复杂的特定于任务的组合。我们提出了 UniTable,一个统一了 TR 的训练范式和训练目标的训练框架。其训练范例将纯像素级输入的简单性与来自各种未注释表格图像的自我监督预训练所赋予的有效性和可扩展性结合起来。我们的框架将所有三个 TR 任务的训练目标(提取表结构、单元格内容和单元格边界框)统一为一个与任务无关的统一训练目标:语言建模。广泛的定量和定性分析凸显了 UniTable 在四个最大 TR 数据集上的最先进 (SOTA) 性能。UniTable 的表解析能力已经超越了现有的 TR 方法和通用大型视觉语言模型,例如 GPT-4o、GPT-4-turbo with Vision 和 LLaVA。我们的代码可在此 https URL 上公开获取,其中包含一个 Jupyter Notebook,其中包含完整的推理管道,跨多个 TR 数据集进行了微调,支持所有三个 TR 任务。

四、小结
本篇文章介绍如何在文档中提取表格的结构信息,在介绍方案前先介绍了表格的类型,然后介绍了三种方案来如何提取文档中的表格结构,最后我们可以针对自身场景来选择相应的方案。