更新于:2024-05-31 22:00
一、简介
所谓 word 版面识别与 pdf 映射,主要针对 word 文件解析后在网页端展示困难的问题。word 是一种实时渲染的文件,不同软件打开可能会存在排版差异,pdf 不存在排版问题,但是 pdf 却丢弃元素信息。如果将两者优点结合起来会是什么样子呢?
我们通过将 word 中各类元素进行渲染,再将其转换成 pdf,通过 pdf 得到每个元素坐标信息,从而实现将两者的优点相结合,进而完成相互之间的映射关系。
二、架构和代码展示
1、流程架构设计
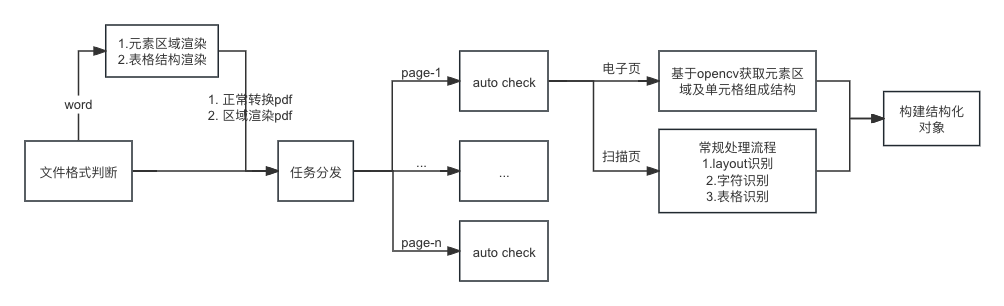
上图是绘制一个基于 word 的解析流程架构图,当 word 文件不存在部分页面是全图覆盖内容时,该架构可摆脱各种CV或NLP模型去解析。图中的渲染步骤,是用于代替常规处理流程中的layout识别和表格识别。当 word 文件内容不存在歧义时(例:常见的研报类型首页,通过无线表格做文本元素排版),是可以做到百分百还原版面信息(从人类理解的角度),并且该流程解析速度快,能和 PDF 做映射,方便在网页端展示原始信息。
2、代码展示
下面提供一段由gpt-4o提供的对 docx 文件渲染的代码,仅供参考,请勿在生产环境使用。
from docx import Document
from docx.shared import RGBColor
from docx.oxml.ns import qn
from docx.oxml import OxmlElement
def set_cell_background(cell, color):
cell._element.get_or_add_tcPr().append(
OxmlElement('w:shd', {
qn('w:val'): 'clear',
qn('w:color'): 'auto',
qn('w:fill'): color
})
)
def color_run(run, color):
run.font.color.rgb = color
def color_paragraph(paragraph, color):
for run in paragraph.runs:
color_run(run, color)
def color_section_headers_footers(section, color):
for paragraph in section.header.paragraphs:
color_paragraph(paragraph, color)
for paragraph in section.footer.paragraphs:
color_paragraph(paragraph, color)
doc = Document("demo.docx")
for paragraph in doc.paragraphs:
if paragraph.style.name.startswith('Heading'):
color_paragraph(paragraph, RGBColor(255, 0, 0))
for paragraph in doc.paragraphs:
if not paragraph.style.name.startswith('Heading'):
color_paragraph(paragraph, RGBColor(0, 255, 0))
for section in doc.sections:
color_section_headers_footers(section, RGBColor(0, 0, 255))
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
set_cell_background(cell, "FFFF00")
for paragraph in doc.paragraphs:
if paragraph.style.name == 'TOC Heading' or paragraph.style.name.startswith('TOC'):
color_paragraph(paragraph, RGBColor(255, 165, 0))
doc.save("demo_1.docx")
上面代码是通过python-docx对 docx 文件进行渲染,简单易用,但是缺点也有不少,我们列举一些。
1. 效果问题:python-docx解析docx效果可以,但解析稍微复杂点样式的word时,就会出现多处元素区域无法渲染现象;
2. 格式支持:python-docx由于是读取ooxml获取信息,因此对于doc、rtf、wps等其他文件格式就不兼容了。
由于缺点比较致命,在这里推荐之前文章 基于ooxml协议解析office文件 中用到的工具,把相关代码从解析转换成染色即可,效果问题无需担心,不会出现区域遗漏问题,另外格式问题也是迎刃而解。
渲染一些元素没什么太大的问题,主要是表格的单元格结构获取相对繁琐些,这里也列举一些方案。
1. 增强表格线条信息:通过修改单元格对象的边框信息,作用于后续解读线条信息,提高线条识别准确率。
2. 解析单元格结构:读取表格对象中单元格的合并信息和各单元格内容,将其信息返回作用于后续单元格构建。
3. 渲染单元格:用不同颜色将单元格渲染,便于在pdf中定位单元格坐标以及合并信息等。
第一种方案会修改原始文件,可能会导致 word 整体布局发生变化,另外如果线条识别不好也不能保证百分百正确。第二种方案会增加一些额外的信息输出,涉及字符搜索。第三种方案相对简单些,类似文章 如何提取文档中的表格信息 的LGPMA单元格检测模型,要想保证 word 中相邻单元格颜色不同,需要借助地图染色的四色定理,可以参考之前的文章 使用四色定理处理问题 。
三、效果展示和方案弊端
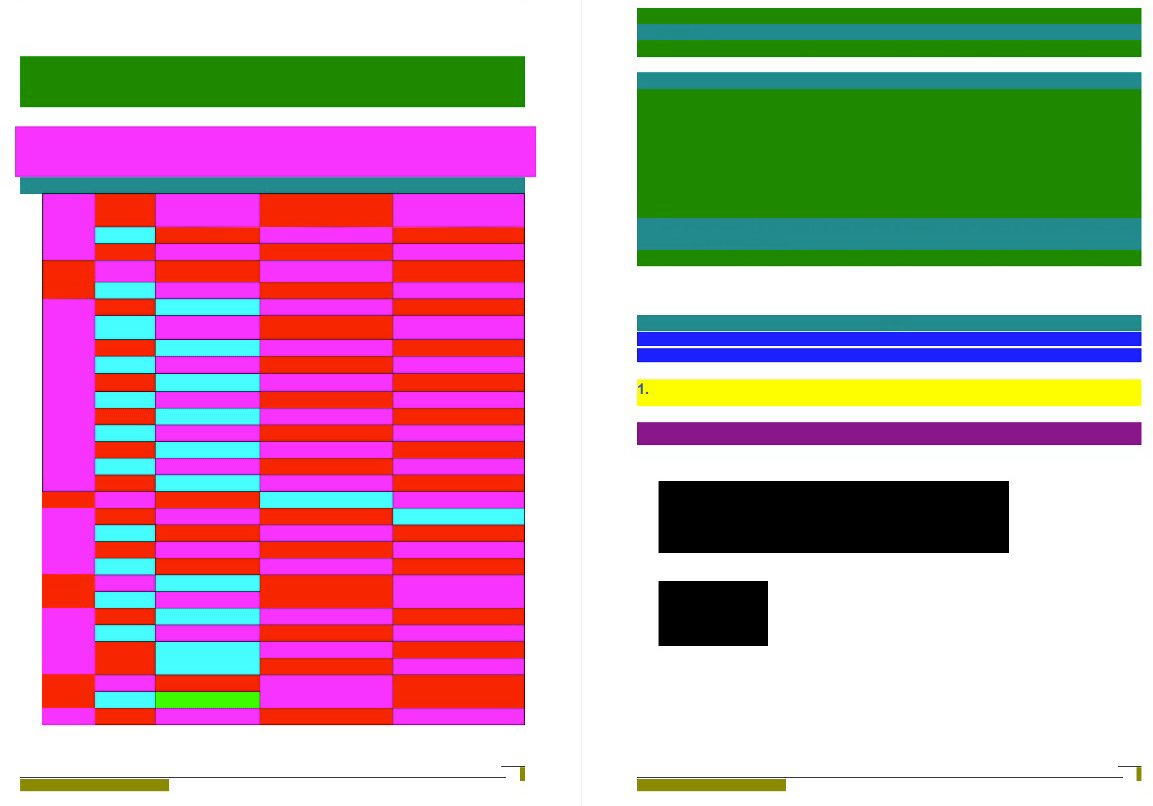
上面我们提到了 word 不存在内容歧义,这个确实是该方案但一个弊端,但是上面架构可以设置输入参数设置跳过相关页面使用渲染区域识别(针对样本类型设置参数即可)。另外就是 word 自身规范导致,例如跨页表头行继承场景,下页的表头行无法被选中,但是转换的pdf却真实存在(即会丢失一行单元格的渲染),上面提到的表格元素处理的三种方案中,只有方案一不受影响(无奈),好在这类场景不多,另外可以借助合并跨页表格可以规避效果展示。
四、小结
本篇文章介绍了一种 word 的 版面识别方案,将通过 word 协议码获取元素信息的便捷和 pdf 的展示优点相结合,做到了两者的映射。可不依靠模型算法也能做到很好的解析效果,是个不错的方案,总体实现起来也相对简单。